Contents
1. Introduction
2. Description of Terms
3. SMP and MPP
4. Why Is the New SMP Fast?
5. Reasons the New MPP Solver is Efficient at High Parallelism.
6. The Relationship Between Hardware Performance and Parallel Solver Speed Gain (Common to SMP and MPP)
7. The Relationship Between Hardware Performance and Parallel Solver Speed Gains (MPP Edition)
8. Summary
9. References
1. Introduction
Lead times for the competitive design of automobiles and electric appliances are getting shorter and more unforgiving each year. One way to reduce design lead time is to incorporate Computer Aided Engineering (CAE). In particular, CAE related to electromagnetism often uses finite element analysis (FEA), and reduction of analysis time is in great demand with users.
One good solution is to increase speed using parallel processing. Hardware configurations influence software algorithms and affect parallel performance greatly, and hardware advances in recent years have been remarkable. This means that software algorithms also need to advance to keep up. At JMAG, we implement algorithms that are best suited for the latest hardware, and we produce some of the highest levels of parallel performance in the industry. In particular, the shared memory type parallel (SMP) solver described below is greatly improved in version 16.1, and the distributed memory type massively parallel (MPP) solver is vastly improved in version 17.0.
In this white paper, we will explain why the new SMP and MPP parallel solvers are fast from the perspective of the algorithms used. Additionally, we will attempt to clarify the influence of hardware system environments on SMP and MPP.
This document can be thought of as pointers and precautions for hardware selection and software operation.
2. Description of Terms
In this white paper, the following terms are used.
Node:Here, one computer is assumed.
Cluster:
A system that connects two or more nodes in a high-speed network.
CPU:
The central processing unit installed in each node. Equivalent to the processor. Recent CPUs have multiple cores.
Core:
An arithmetic processing unit (APU).
Process:
Unit of program execution. For example, when launching JMAG-Designer, a process named "designer.exe" is displayed in Windows Task Manager.
Thread:
The smallest unit of processing that uses the core in program execution. For example, in single-threaded processing, only one thread runs in the core per process. In the case of multithreading, one process has multiple threads and multiple cores are utilized.
3. SMP and MPP
In the SMP parallel solver, as shown in Fig. 1, parallel processing is performed using multiple cores. This is generally known by the term "thread parallelism". Since parallel processing operates within one node only, processing with degrees of parallelism exceeding the number of cores installed in the node is not possible.
With the MPP parallel solver however, multiple processes are generated with the same name that perform parallel processing while maintaining communications between the processes. This is generally known as "process parallelism". Thanks to communication processing, parallel processing can be performed on clusters that cross nodes as shown in Fig. 2, and not just within a single node. For JMAG's SMP and MPP parallel solvers, each new and old solver name is organized as shown in Table 1.
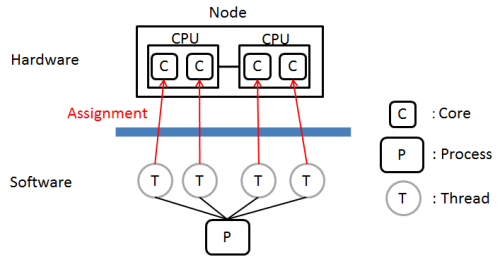
Fig.1 General concept of SMP parallel processing (Example of 4x parallel)
Calculations are performed in a single process, and multiple threads are processed in parallel within one node.
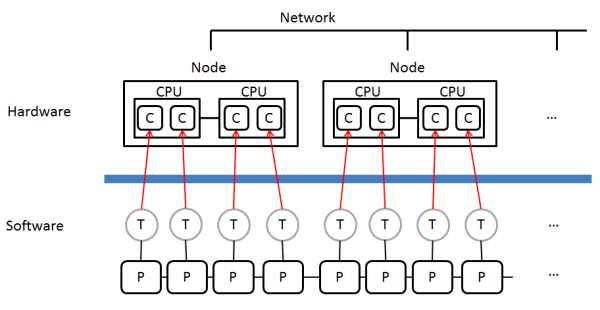
Fig. 2 General concept of MPP Parallel Processing (remarks are the same as in Fig. 1)
Calculations are handled in multiple processes, each assigned to a different core.
You need to sign in as a Regular JMAG Software User (paid user) or JMAG WEB MEMBER (free membership).
By registering as a JMAG WEB MEMBER, you can browse technical materials and other member-only contents for free.
If you are not registered, click the “Create an Account” button.
Create an Account Sign in


