JMAG has a track record of continued pursuit for acceleration through the development and fine-tuning of calculation algorithms. JMAG utilizes the speed of single core acceleration. It also effectively uses hardware to deal with large-scale models to work in parallels.
JMAG released a GPU solver and High parallel solver with enhanced highly parallel processing (HPC) solution.
SMP Solver
Speedup in processing is widely expected in small to medium size models with the shared memory multiprocessing (SMP) parallel solver. JMAG is engaged in development that makes the best use of multi-core machines, such as reducing memory usage and assigning core for multi-thread processing.
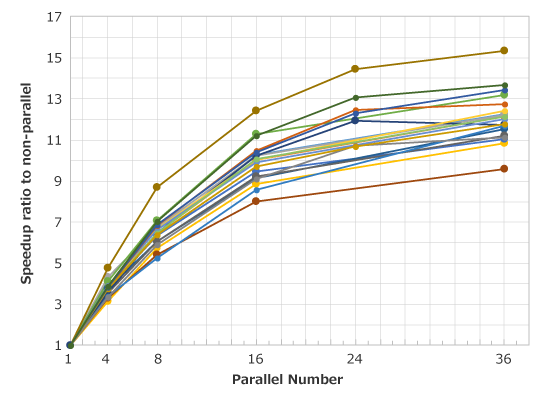
| Application | Analysis type | Element count |
|---|---|---|
| PM motor | TR | 0.35M |
| Generator | TR | 0.42M |
| Stepping motor | TR | 0.75M |
| Transformer | FQ | 1.0M |
Case Studies:
Other, related materials

This document can be thought of as pointers and precautions for hardware selection and software operation....
MPP Solver
This is a parallel solver that uses multiple nodes (machines). JMAG is developing technology to reduce traffic between the nodes. This technology enables the calculation of a large number of parallels in a cluster system. Speedup in processing massively parallels such as 1024 parallels is promising in models with elements on a scale of one million to tens of millions of elements.
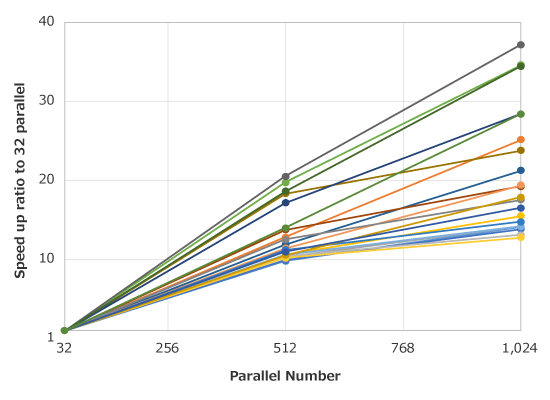
| Application | Analysis type | Element count |
|---|---|---|
| PM motor | TR | 5.1M |
| Axial gap motor | TR | 2.1M |
| Retarder | TR | 2.2M |
| Transformer | FQ | 2.0M |
| Wireless power supply | FQ | 2.0M |
| Induction motor | TR | 2.1M |
| Induction heating | FQ | 5.1M |
Case Studies:
AC copper loss analysis of Interior Permanent Magnet motors

The 3D model that reproduces a coil shape is 780,000 elements in scale. Transient phenomena that occurs due to AC copper loss is accounted for, and 91 analysis steps for 2 electrical angles periods are run.
Calculation approximately takes two hours using MPP256 parallel. If a calculation at a single operating point is finished in two hours, AC copper loss at more operating points can be evaluated and more accurate efficiency evaluation can be made.
| CPU | Intel Xeon Gold 6138 |
| Clock frequency(GHz) | 2.0 |
| Number of cores / processor | 20 |
| Number of processors / node | 2 |
| Memory (GB) / node | 192 |
| Number of nodes | 24 |
| Network | Infiniband (QDR) |
This document compares an efficiency map obtained with simulations with an efficiency map consisting of actual measurements, achieving an error of 1% ...
Other, related materials
To accurately obtaining the end-winding eddy current loss at high rotation speed, the influence of the magnetic field flux generated by the eddy curre...
This document uses as an example an induction heating model to evaluate the performance of the highly parallel solver. As a result, it was found that ...
GPU Solver
JMAG is focusing on GPGPU (General-purpose computing on graphics processing units) used for numeric calculations with the exception of image processing and provides solvers that support GPGPU.
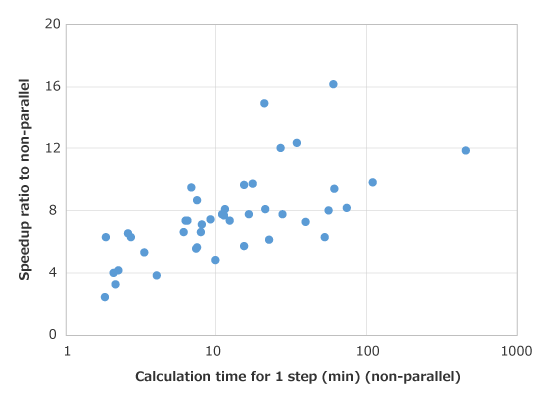
Speedup is conducted efficiently by using GPU in calculation parts of the linear solver, as well as simultaneously using CPU parallels for other processing.
In particular, a noticeable increase in processing speed can be seen in a model where calculation time for a single step (there are a large number of elements or calculation for the linear solver takes time) takes a long time.
| Application | Analysis type | Element count |
|---|---|---|
| Induction motor | TR | 1.4M |
| PM motor | TR | 1.1M |
| PM motor | TR | 1.4M |
| Speaker | TR | 1.2M |
| Magnetic head | TR | 1.1M |
| Retarder | TR | 1.3M |
| Induction heating | FQ | 1.0M |
| Bus bar | FQ | 1.5M |
| GPU | NVIDIA GeForce RTX 2080 Ti |
| CPU | Intel Core i9-10800KF |
| Clock frequency (GHz) | 3.7 |
| Number of cores / processor | 10 |
| Number of processors / node | 2 |
| Memory (GB) | 64 |

